Giriş
Consistent Hashing, dağıtık sistemlerde istekleri dağıtmak işinde çok kullanılır.
1. Faydası Nedir?
En büyük faydası klasik HashMap tarzı veri yapılarındaki rehashing() maliyetinden bizi kurtarması. Böylece bir düğüm silinince tüm dünya yer değiştirmiyor, sadece silinen düğüme ait key değerler geriye kalan düğümlere eşit şekilde dağıtılıyor.
Bu da tam olarak bir dağıtık sistemin istediği şey. Yani en az yer değişikliği. Consistent Hashing her zaman dairesel olarak gösteriliyor.
2. Algoritma
Açıklaması şöyle. İlk olarak 1997 yılında yayınlanıyor, ancak 2007 yılına kadar yaygın değil
In 1997, the paper “Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web” was released. This paper described the approach used by Akamai in their distributed content delivery network.
It took until 2007 for the ideas to seep into the popular consciousness. That year saw two works published:- last.fm’s Ketama memcached client.
- Dynamo: Amazon’s Highly Available Key-value Store
These cemented consistent hashing’s place as a standard scaling technique. It’s now used by Cassandra, Riak, and basically every other distributed system that needs to distribute load over servers.
Algoritma şöyle
Consistent Hashing is organized in the following manner:1. The servers are hashed using their IP addresses and assigned the position based on the hashing function.2. Similarly, the keys are hashed to positions using the same hashing function and placed in the virtual ring.3. Map the keys with the server having the same position, and in case the position don’t match, then assign the key to the first server that we get while moving in a clockwise direction.Hence in this manner, the keys are assigned to the server in Consistent Hashing. The beauty of Consistent Hashing comes when we add or remove servers.
Bir başka anlatım şöyle
You can think of the circle as all integers 0 ..2³²-1. The basic idea is that each server is mapped to a point on a circle with a hash function. To lookup the server for a given key, you hash the key and find that point on the circle. Then you scan forward until you find the first hash value for any server.
Birinci maddede sunucuları çembere yerleştirmek için IP adresleri kullanılır deniliyor ancak her hangi başka bir özellik te kullanılabilir. Açıklaması şöyle
.... use any server related info to find out the hash, eg, IP address) to store our objects and servers on this circle, i.e, our hash ring
Şeklen şöyle. Burada hash değeri saat yönünde bir sonraki sunucuya yönleniyor. Algoritma saatin tersi yönünde de kullanılabilirdi. İkisi arasında bir fark yok

Eğer D sunucusunu eklersek şeklen şöyle. Burada C'ye giden yük artık ikiye bölündü. Bir kısmı D'ye yönlendi, bir kısmı da değişmedi.


Ancak bu algoritmada bir eksiklik var. O da Non-Uniform Distribution.
3. Algoritmada Bir Düzeltme - Non-Uniform Distribution Eksikliği
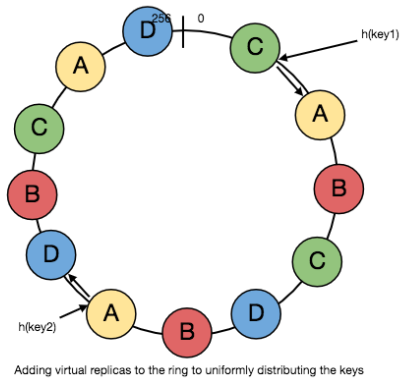
Non-Uniform distribution eksikliği için açıklama şöyle. Yani zaman içinde tüm yük belli sunuculara yığılmaya başlıyor. Bunu düzeltmek için sunucu birden fazla kez ekleniyor. Yani aynı sunucundan Server1 mesela 2 tane var. Bu sunuculara vnode veya replica deniliyor.
There is a shortcoming of this approach. All the keys may get mapped to the same server, and hence one server will get all the workload, and all the other servers will remain idle. This situation is very inefficient and is very prone to failure. To deal with this, a new concept has been introduced. All the servers are replicated and arranged at different positions in the ring. In this manner, with an increased number of servers, the distribution becomes much uniform and helps in the service’s scaling.
Bir başka açıklama şöyle
In practice, each server appears multiple times on the circle. These extra points are called “virtual nodes”, or “vnodes”. This reduces the load variance among servers. With a small number of vnodes, different servers could be assigned wildly different numbers of keys.
(A brief note on terminology. The original consistent hashing paper called servers “nodes”. Papers will generally talk about“nodes”, “servers”, or “shards”.
Şeklen şöyle

Bir başka şekil şöyle
4. VNode Durumu Tam Düzelmiyor
Açıklaması şöyle
Ring hashing presents a solution to our initial problem. Case closed? Not quite. Ring hashing still has some problems.
First, the load distribution across the nodes can still be uneven. With 100 replicas (“vnodes”) per server, the standard deviation of load is about 10%. The 99% confidence interval for bucket sizes is 0.76 to 1.28 of the average load (i.e., total keys / number of servers). This sort of variability makes capacity planning tricky. Increasing the number of replicas to 1000 points per server reduces the standard deviation to ~3.2%, and a much smaller 99% confidence interval of 0.92 to 1.09.
This comes with significant memory cost. For 1000 nodes, this is 4MB of data, with O(log n) searches (for n=1e6) all of which are processor cache misses even with nothing else competing for the cache.
5. Diğer Seçenekler
Bazı diğer algoritmalar şöyle. Her birisinin kendisine göre artı ve eksileri var
- Jump Hash
- Multi-Probe Consistent Hashing
- Rendezvous Hashing
- Maglev Hashing
6. Kod
Örnek
Örnek
Şu satırı dahil ederiz
import java.util.Collection;import java.util.SortedMap;import java.util.TreeMap;import com.google.common.hash.HashFunction;
Şöyle yaparız. Bu kodda numberOfReplicas değişkeni ile non-Uniform Distribution da ele alınıyor.
public class ConsistentHash<T> {private final HashFunction hashFunction;private final int numberOfReplicas;private final SortedMap<Integer, T> circle = new TreeMap<Integer, T>();public ConsistentHash(HashFunction hashFunction, int numberOfReplicas,Collection<T> nodes) {this.hashFunction = hashFunction;this.numberOfReplicas = numberOfReplicas;for (T node : nodes) {add(node);}}public void add(T node) {for (int i = 0; i <numberOfReplicas; i++) {circle.put(hashFunction.hash(node.toString() + i), node);}}public void remove(T node) {for (int i = 0; i <numberOfReplicas; i++) {circle.remove(hashFunction.hash(node.toString() + i));}}public T get(Object key) {if (circle.isEmpty()) {return null;}int hash = hashFunction.hash(key);if (!circle.containsKey(hash)) {SortedMap<Integer, T> tailMap = circle.tailMap(hash); //>= yani saat yönündehash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();}return circle.get(hash);}}
From a programming perspective, what we would do is keep a sorted list of server values (which could be angles or numbers in any real interval), and walk this list (or use a binary search) to find the first server with a value greater than, or equal to, that of the desired key. If no such value is found, we need to wrap around, taking the first one from the list.To ensure object keys are evenly distributed among servers, we need to apply a simple trick: To assign not one, but many labels (angles) to each server. So instead of having labels A, B and C, we could have, say, A0 .. A9, B0 .. B9 and C0 .. C9, all interspersed along the circle. The factor by which to increase the number of labels (server keys), known as weight, depends on the situation (and may even be different for each server) to adjust the probability of keys ending up on each. For example, if server B were twice as powerful as the rest, it could be assigned twice as many labels, and as a result, it would end up holding twice as many objects (on average).
- add() metodunda her node isminin numberOfReplicas kadar eşit dağılacak şekilde TreeMap'e eklendiği görülebilir
- get() metodunda tailMap() ile >= anahtar değerine sahip SortedMap bulunuyor. Eğer SortedMap boş ise circle.firstKey() ile ilk eleman döndürülüyor
- Eğer remove() ile bir tane node silinirse bile, mevcut atamalara bir şey olmuyor. Yani A0'a atanmış değer yine A0'da kalıyor. Sadece silinen node - mesela C olsun - ile ilgili atamalar farklı yerlere dağıtılıyor. Açıklaması şöyle
So, what’s the benefit of all this circle approach? Imagine server C is removed. To account for this, we must remove labels C0 .. C9 from the circle. This results in the object keys formerly adjacent to the deleted labels now being randomly labeled Ax and Bx, reassigning them to servers A and B.But what happens with the other object keys, the ones that originally belonged in A and B? Nothing! That’s the beauty of it: The absence of Cx labels does not affect those keys in any way. So, removing a server results in its object keys being randomly reassigned to the rest of the servers, leaving all other keys untouched:
Hiç yorum yok:
Yorum Gönder